-

2021: A TraxSolutions Recap
Our product engineering team, as part of the client-focused TraxSolutions team, had a very busy 2021.To demonstrate just how much......
-

Modular Construction, Wholesale Concept
For our clients, one of the most useful words to associate with any TraxSolutions® module is “integrated”. We conceptualize and......
-
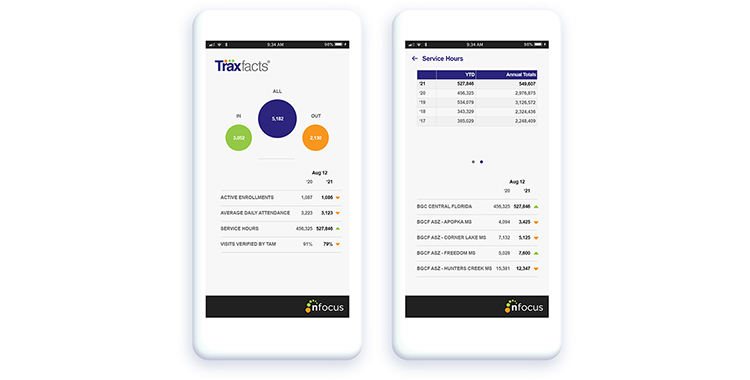
Exciting Days In The Shop
A new software tool is on the way from nFocus Solutions – an executive-focused attendance/reporting module we call TraxFacts which......
-

TraxFacts® – Tomorrow’s Executive-Level Data Is Here
We base the foundation of all product development on an understanding of what our clients actually need. What we’ve learned......
-

Software That’s Simple Is Software You Need
Overcomplicated solutions are common these days, especially in the software profession. For some reason, computer technology tends to lead people......
-

Scouting Success Upfront
You see it here and there in the software business – the assumption that every challenge and every objective will......
-

Tech is My Career, Partnership is My Goal
Thoroughness counts for a lot in my world. From product development to quality assurance, rollouts to system upgrades, we do......
-

Community Data-Sharing 101: The Data-Sharing Agreement as a Living Document
THE FOUNDATION In my last blog entry, I gave general advice about writing a Data Sharing Agreement (DSA), using......
-
Community Data-Sharing 101: Demystifying the Data-Sharing Agreement
If you’ve been following my blog to date, you can see the high level of forethought, work, and skill that......
-

Community Data-Sharing 101: Picking a Data Steward Partner
As one of the final stages of the partnership-building phase of a data-sharing project, you must pick which of your......